分布式数据库设计与实现 数据处理和存储支持服务
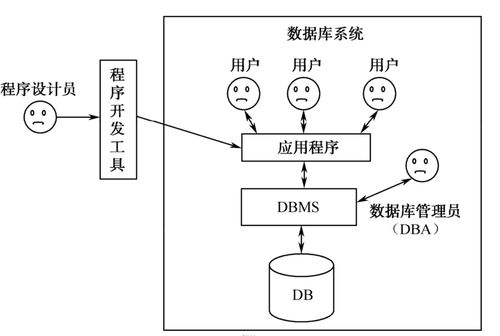
随着互联网技术的飞速发展,数据量呈爆炸式增长,传统的集中式数据库在扩展性、可靠性和性能方面面临严峻挑战。分布式数据库应运而生,它通过将数据分散存储在多台独立的服务器上,提供了高效的数据处理和存储支持服务。本文将从设计原则、关键实现技术以及服务支持三个方面,探讨分布式数据库的核心内容。
一、分布式数据库设计原则
分布式数据库的设计旨在满足高可用性、可扩展性和一致性等需求。数据分片是基础设计原则,通过水平或垂直分片将数据分布到不同节点,以平衡负载并提高查询效率。采用冗余备份机制,如副本复制,确保数据在节点故障时不会丢失,提升系统的容错能力。设计时需考虑一致性协议,例如基于Paxos或Raft的共识算法,以保障分布式环境下数据的一致性。设计应支持弹性伸缩,允许动态添加或移除节点,适应业务量的变化。
二、关键实现技术
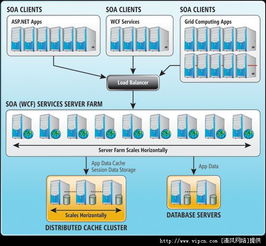
在实现分布式数据库时,核心技术包括数据分布策略、事务处理和查询优化。数据分布策略涉及分片键的选择和分布算法,如一致性哈希,以减少数据迁移开销。事务处理需支持分布式事务,常用方法如两阶段提交(2PC)或基于时间戳的并发控制,确保ACID特性。查询优化则通过分布式查询引擎,将全局查询分解为局部子查询,并行执行以提高性能。数据存储层通常采用列式或行式存储,结合压缩和索引技术,优化存储效率和访问速度。
三、数据处理和存储支持服务
分布式数据库不仅提供数据存储,还集成了强大的数据处理和存储支持服务。在数据处理方面,它支持实时流处理、批量分析和机器学习集成,例如通过Spark或Flink框架进行复杂计算。存储服务则包括多副本管理、自动故障恢复和数据生命周期管理,确保数据持久性和可用性。服务层提供监控、备份和安全管理工具,帮助用户高效运维。例如,云原生分布式数据库(如Google Spanner或Amazon DynamoDB)还提供了全球分布、低延迟访问的服务,满足全球化业务需求。
分布式数据库的设计与实现是一个系统工程,它通过先进的分片、复制和一致性技术,构建了可靠的数据处理与存储支持服务。随着人工智能和物联网的发展,分布式数据库将继续演进,为企业提供更智能、更高效的數據管理解决方案。
如若转载,请注明出处:http://www.zhaocebao.com/product/19.html
更新时间:2026-03-02 19:18:55